避坑指南!数据分析最容易被忽略的7大误区 | 帆软九数云

本文旨在帮助大家正确认识数据分析中的“误判”现象,避免决策上的失误。建立在统计学基础之上的数据分析,照理来说其科学性毋庸置疑,然而在日常事务中仍存在被误导的情况。要想找出问题产生的原因,得先来看下数据分析的一般流程。不难发现,数据分析的整个过程都需要人参与。数据是客观的,但解读数据的人是主观的,因此在涉入时会存在踏入误区的可能。若错误地理解数据,致使分析结果与事实不一致,就会引起决策失误。接下来小九来介绍在数据分析过程中常见的几个误区,为大家的数据分析之路扫清障碍。

01认为数据分析很高大上
许多人提到数据分析,就觉得那只是少数掌握高级的分析方法或者分析模型的人的事情。其实不然,真理至简。各种看起来复杂的分析方法和分析模型,都是由简演变而来的。
以分析模型举例,我们常见的ABC分析、AARRR分析、RFM分析、购物篮分析、用户留存分析等等,都是经过验证的简单有效的分析模型。我们根据不同情况用这些模型,就是站在“前人的肩膀”上做分析。

(九数云分析模型)
再回到分析工具上,做数据分析也并不要求大家都掌握 Python、精通算法,只要有合适的分析方法和分析模型,找到关键性的指标,我们每个人都能用九数云、Excel这样的简易工具完成分析。
02认为需要大数据才能支撑分析
日常我们听到数据分析,往往都是和“大数据”这个词挂钩,但实际上两者并无任何依赖关系,更多是在炒作大数据这个概念。数据分析需要特定的数据,而不是更多的数据。
大数据在很多情况下,其实是无法人力剔除脏数据的情况下的方案,通过放大数据量,减少这些内容的影响。这种对于实际业务毫无意义的脏数据破坏性比较大,对指标的准确度影响也较大。
所以如果我们的样本,已经可以反映全量数据、具有较好的质量,那就可以直接针对特定业务进行分析,并且得到的结论也具有足够的可信度。
03脱离实际业务
分析是无止境的,因为有着无穷无尽的变量。但我们不能为了分析而分析,任何脱离实际业务的数据分析都只能沦为一盘散沙,所以我们必须带有明确的目的性去分析数据。
解决这个误区最管用的办法,首先就是要找到最核心的指标(北极星指标)。举个例子,比如我们当前核心目标是app促活;再明确我们能做的事情,比如分析发现给的红包力度越大,用户越频繁使用,留存率越好。但这明显不是可行方案。那我们最终的结论很可能是长期通过运营内容,周期性通过红包促活,这样才能保证合理的获客成本,实现良性的循环。
04过分依赖数据
过分依赖数据,一方面会让我们自己做很多没有价值的数据分析;另一方面,也会限制本身应有的灵感和创意。数据分析是达到目标的一个科学手段,但不是唯一的手段,过分依赖数据会变得不科学。
当数据缺失或是问题简单时,数据分析并不是必要的步骤。假如你去造一个汽车,分析以往马车的情况意义不大,甚至还限制了对汽车舒适度和速度的想象。
05辛普森悖论
先通过一个案例了解一下什么是辛普森悖论:

这个表格中,不管是商学院,还是法学院,男生的录取比例都比女生高很多,但是总体来看,女生录取率却是男生的两倍。这种在分组比较中都占优势的一方,在总评中有时反而是失势的一方的情况,就是辛普森悖论。
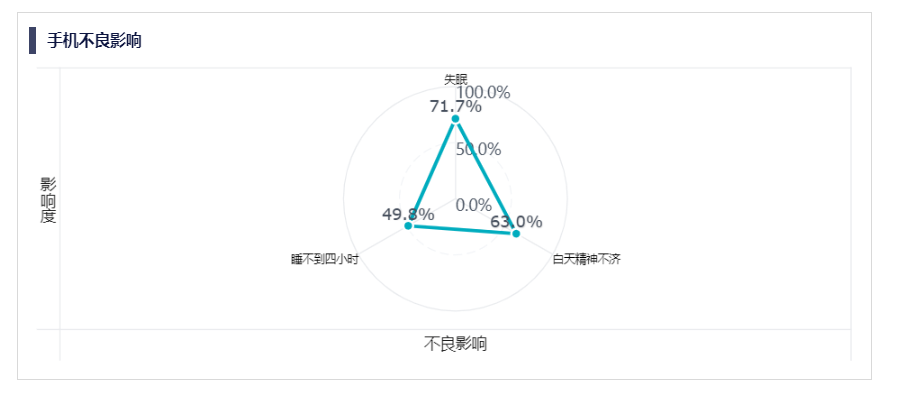
再举一个用户分析的例子。1. 结合图表可知,某应用的用户每日平均访问时长提升了。我们可以得出结论:用户的粘性提升了。
图片
2. 但这个结论不一定就是正确的。如果此时我们把用户根据类型拆分来看,可能会得到如下的结论:核心用户和非核心用户的日均访问时长都没有变化。

3. 这个结论似乎与之前的结论相悖。所以此时我们就可以进一步分析,去查看核心和非核心用户的占比情况。
通过图表可知:核心用户占比提升了,才拉高了整体的日均访问时长。

4. 分析到这其实还没结束,因为这个结论很有可能还有“坑”。我们需要再看一下各类用户的具体数量。
于是我们得出了最终结论:原来是非核心用户的减少,有大批用户的流失,才让产品的指标看上去显得变好了。

因此,我们不能只是看最终日均访问时长结果,更应该加上用户数这个观测指标,或是通过合理的规划,将用户数的作用体现在最终指标里。
回避辛普森悖论的方法是:
1.斟酌个别分组的权重,以一定的系数去消除以分组资料基数差异所造成的影响。
2.了解该情境是否存在其他潜在要因而进行综合考虑。
这里在平均值一文中有给大家介绍,详情参见:平均值的秘密。
06因果陷阱
在介绍因果陷阱之前,先给大家举日常生活中经常会看到的观点:
打篮球能让人长高。
喝咖啡可以长寿。
不吃早饭容易变胖。
会撒娇的女人更好命。
然而事实并非如此。下面我们来分别给出这几个常见观点隐藏的因果陷阱:

07幸存者偏差
在讲述幸存者偏差之前,先给大家举几个例子:
淘宝上卖极限运动设备的商家,尤其卖降落伞、滑翔伞的卖家好评都是满的,从来没有差评(出事故的人:“我倒是想有差评的机会。”)。别人家的孩子都比你强(日常接触会放大瑕疵,偶尔接触会放大优点)。读书无用论、成功学(天时地利人和缺一不可,哪怕只从自己身上看,态度勤奋可以争取,挫折都可以模仿,但头脑远见几乎不能复制。)
幸存者偏差出现的原因是逻辑和统计上出现了错误,本质是统计时忽略了样本的随机性和全面性,用局部样本代替了总体随机样本,从而对总体的描述出现偏差。当然,幸存者偏差还很大程度上反映了人性的弱点,人性总是会让我们忽略或筛选信息,最终导致幸存者偏差的现象产生。
要避免幸存者偏差有以下几个方法:
1.关注沉默的数据,当我们已经习惯了在热搜上看到年入百万、豪车豪宅,拼多多的崛起让「沉默证据」发力:原来下沉市场才是更为广阔的人群。
2.学习数学统计知识,避免公式错误。就像讲述辛普森悖论里的案例,表面欣欣向荣,其实暗藏了用户流失的风险。
3.提升认知水平和逻辑思维能力,发生幸存者偏差很大程度是因为认知不够宽广,只知道表面信息,没抓住关键信息,最后导致判断失误。
数据分析
数据分析之路存在很多隐形的“坑”,看似是建立在客观事实和数据之上的雄辩,到最后可能还是会沦为诡辩。
大数据时代,企业数据体量不断扩大,业务需求和数据分析环境也在时刻变化。所以在处理和分析数据时,我们都应该在业务场景下进行综合考虑,做到不为数据量的多少所羁绊,不过分依赖数据,有的放矢地得出结论,让客观数据和主观意识完美融合。

热门产品推荐


复诊率计算公式与提升策略,优化患者体验,增强满意度,快来了解吧!
九数云 | | 2025-03-06
九数云 | | 2025-03-06
在当今竞争激烈的市场环境中,企业要想脱颖而出,提高生产效率统计分析表至关重要。一个结构化和科学化的生产效率统计分析表是现代制造型企业数字化管理和精益生产不可或缺的基础工具。通过系统地记录和分析生产过程中的各项数据,企业可以清晰地掌握生产脉搏,找出瓶颈和问题,进而优化生产流程,实现产能飙升。
九数云 | | 2025-08-27

大数据推动时代发展的今天,传统零售行业面临着重大变革。新零售如何将传统的“人”“货”“场”三者进行高效的连接,达成更多、更快、更好、更省的目标呢?离不开数字化工具-九数云!
九数云 | | 2023-02-14
数字化景区是运用先进科技重塑旅游体验与管理模式的创新实践。它融合了人工智能、大数据、物联网以及VR/AR等前沿技术,旨在构建一个集虚拟仿真、实时监控和沉浸式体验于一体的智慧旅游生态系统。通过科技赋能,数字化景区不仅能够提升游客的参与感和满意度,还能显著提高景区的运营效率和管理水平,为旅游业的转型升级注入新的活力。
九数云 | | 2025-12-23
以上就是power bi 使用的介绍了,希望能解决你的问题!
九数云 | | 2022-10-25